 Редакция Rookee
Редакция Rookee 





Яндекс запустил новый поисковый алгоритм, который работает на основе нейронных сетей. «Палех» поможет Яндексу лучше подбирать ответы на редкие и уникальные поисковые запросы.
Впервые поиск использует нейронные сети для того, чтобы находить документы не по словам (которые используются в запросе и в самом документе), а по смыслу запроса и заголовка.
Предпосылки
При подборе ответов на запросы нельзя опираться только на слова: один и тот же смысл можно выразить совершенно по-разному. В этом случае нужны дополнительные данные, например, обезличенная статистика: на какие страницы перешли пользователи, задавшие такой же запрос. В случае с уникальными запросами статистики мало или нет вовсе — поэтому Яндексу трудно понять, какие страницы хорошо отвечают на запрос, а какие нет.
Поисковая модель на нейронных сетях, которую использует «Палех», умеет устанавливать смысловые соответствия между поисковым запросом и заголовками страниц. С её помощью можно выявить, что в запросе и на странице говорится об одном и том же, даже если у них нет общих ключевых слов. Так, поиск поймёт, что в запросе [фильм про человека который выращивал картошку на другой планете] речь идёт о «Марсианине», хотя релевантные страницы могут и не содержать слов «картошка» или «планета».
Почему «Палех»
Редкие и уникальные запросы составляют почти треть всего потока поисковых запросов, поэтому иногда их называют «длинным хвостом» поиска. Новому алгоритму решили дать название «Палех» в честь Жар-птицы — сказочной птицы с длинным хвостом, которая часто появляется в сюжетах палехской миниатюры.
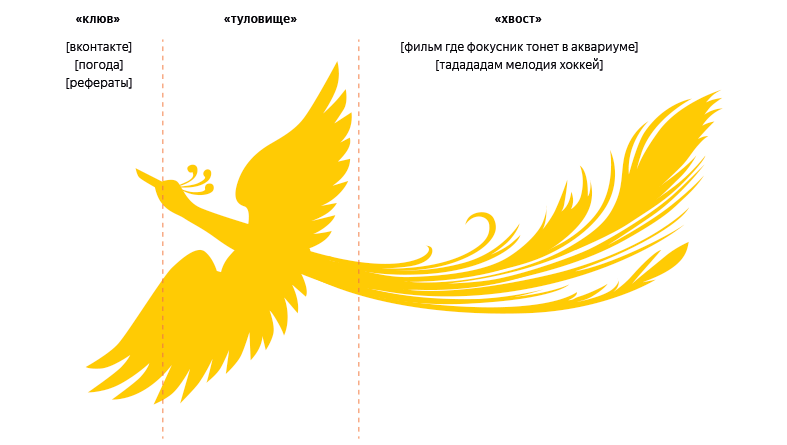
Более подробно об алгоритме «Палех» и особенностях поисковых запросов из «длинного хвоста» Яндекс рассказал своем . О том, как разработчики поиска обучали нейронную сеть обрабатывать редкие и уникальные запросы, можно узнать в статье на «».




